
Spectrum-X is the world’s first comprehensive end-to-end Ethernet solution specifically designed for generative AI. It consists of the Spectrum-4 series switches, Bluefield-3 DPU network
cards, LinkX 400G cables for end-to-end connectivity, and a complete stack of software solutions with hardware acceleration support. Therefore, Spectrum-X is a tightly integrated software
and hardware solution, where each component alone cannot achieve its maximum value.
As of today, leading chip manufacturers have already introduced dedicated chips for the AI and ML fields, and have increased the single-chip rate to 51.2Tbps. Examples include Broadcom’s
Tomahawk5, Jericho3-AI (14.4T), Marvell’s Teralynx10, Cisco’s SiliconOne G200, and of course, NVIDIA’s Spectrum-4 chip. However, can traditional data center switching chips not be
used in AI scenarios? Of course, they can, but their efficiency will be significantly lower. Let’s take a closer look at the reasons why traditional Ethernet is not well-suited for running AI
workloads, which primarily involve training and inference
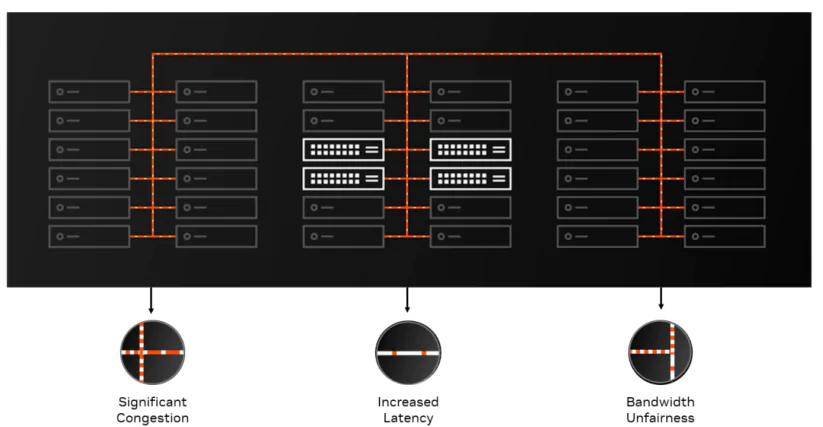
1.Disadvantages of traditional Ethernet in AI training
(1) Uneven Load on ECMP Bandwidth
Traditional Ethernet in data centers is typically used for applications such as web browsing, audio and video streaming, and general office internet usage. The traffic characteristics of these
applications include a large number of small flows with relatively even and random distribution of five-tuple values. The establishment and teardown of TCP sessions are also relatively fast,
allowing for even distribution of bandwidth in static hash-based ECMP (Equal-Cost Multipath) multi-path setups.
In contrast, AI large-scale model training involves tightly coupled elements such as AI model and parameters, GPUs, CPUs, and network cards. The network traffic primarily consists of highbandwidth operations like allreduce and alltoall. Typically, each GPU is paired with a high-bandwidth network card, and the number of flow connections established during training processes
is relatively low. However, each individual flow carries a significant amount of data, akin to a large elephant-like flow. In a short period, a few of these elephant flows can consume the entire
bandwidth of a network card.
For example, in an H800 GPU cluster, the AllReduce operation demands a single network card bandwidth of up to 400Gbps. Due to the concentrated distribution of hash entropy, a few
elephant flows can easily congest and block certain ECMP upstream links, while other upstream links remain underutilized. The low number of flows, coupled with high instantaneous
bandwidth per flow, makes it challenging for traditional five-tuple hash-based methods to adapt to this scenario. As a result, the uneven load distribution on ECMP upstream links severely
impacts the overall completion time of AI training.
Currently, there are two main approaches in the industry to address this issue. One approach focuses on optimizing the upper layers by maximizing the number of connections in the AI
computation process through settings in libraries like NCCL, thereby achieving the effect of multiple flows. Alternatively, the IB Verbs API can be used to modify the QP (Queue Pair) fivetuple information within each RoCE (RDMA over Converged Ethernet) connection. This allows for a more diverse distribution of flow five-tuple values, effectively hashing them onto
different links.
The other approach involves manipulating the flow packets directly. For instance, the flowlet technique can divide a flow into packet groups with relatively even gaps between them. Another
method involves fragmenting packets into cells of the same size, treating the fabric composed of small boxes as a large switch to transmit cell packets. There is also the use of per-packet
spray-based techniques to improve overall ECMP bandwidth utilization.
(2) Higher latency and Jitter
Traditional Ethernet applications are based on TCP/IP socket programming, where the CPU copies user data from user space to kernel space and then from kernel space to the network card
driver for interrupt processing and transmission to the destination. This process introduces additional latency and increases CPU load. Therefore, in AI compute clusters, RDMA (Remote
Direct Memory Access) technologies such as InfiniBand or RoCE (RDMA over Converged Ethernet) lossless networks are required. These technologies significantly reduce data transmission
latency by employing kernel bypass and zero-copy techniques. Furthermore, GPU Direct RDMA and GPU Direct Storage technologies leverage RDMA to reduce the latency of GPU memory
data transfers by an order of magnitude. Additionally, NCCL seamlessly supports RDMA interfaces, greatly reducing the development complexity of transitioning AI applications from TCP
to RDMA frameworks.
In large-scale models with billions of parameters, data and model parallelism are often employed, where data is split across multiple GPUs for parallel processing, and parameter updates and
result aggregation are exchanged among thousands of GPUs in various parallel and interconnection structures. Efficient and stable completion of each step in distributed parallel training
becomes crucial. Any issues with a GPU or communication delays within a single node can impact the overall training completion time and introduce bottlenecks in the training process. The
latency of a single node follows the principle of the weakest link, ultimately affecting the overall training acceleration ratio and effectiveness. Therefore, supporting lossless networks with
RDMA technology to reduce network latency and improve overall high-bandwidth throughput is essential in AI network chips.
(3) Poor Congestion Control
Distributed parallel training often encounters occasional many-to-one incast traffic. Traditional Ethernet networks operate on a best-effort mechanism, and even with the best end-to-end QoS
implementation, packet loss or rate limiting can still occur. It often relies on upper-layer transmission mechanisms such as retransmission to compensate for the loss caused by packet loss.
Lossless RDMA Ethernet networks aim to maximize zero packet loss. Two key technologies come into play: per-hop flow control and many-to-one congestion control. In RoCE networks,
these are primarily implemented through PFC (Priority Flow Control) and DCQCN (Data Center Quantized Congestion Notification) mechanisms.
In recent years, many major internet companies have developed their own programmable congestion control mechanisms based on optimizations of DCQCN. These mechanisms utilize
hardware on the endpoint side to send RTT (Round Trip Time) packets to detect network congestion. Combined with in-band telemetry information from each hop’s switches, more accurate
congestion detection can be achieved. Such programmable congestion control algorithms impose higher requirements on both network-side and endpoint hardware chips. Traditional Ethernet
network chips and regular network cards are no longer sufficient to meet the needs of RDMA lossless networks in large AI clusters. As a result, AI network chips and DPUs (Data Processing
Units) that combine endpoint software and hardware have become the preferred choice for leading companies.
2.The Spectrum-X Solution Addresses the limitations of Traditional Ethernet in AI training
(1) The AI Cloud Solution
Firstly, NVIDIA has made a clear distinction between the InfiniBand and AI Ethernet markets through their AI Factory and AI Cloud offerings. The AI Factory caters to a select few CSP
(Cloud Service Provider) major customers with an intense demand for large-scale training of massive language models. They require top-tier infrastructure capable of supporting networks
with tens of thousands of GPUs or more. In this case, NVLink+InfiniBand is the preferred choice. On the other hand, AI Cloud users have different requirements:
A.The solution should provide isolation and support for multiple tenants and training tasks, where individual users may not require significant compute resources, such as various applications
of generative AI.
B.It should enable cloud-native-level containerization and offer flexible resource scheduling capabilities.
C.Compatibility and integration with other Ethernet networks, including network connections utilizing IPv6 or VXLAN, should be supported.
D.It should be compatible with open-source Ethernet protocols and software, such as Sonic and PTP.
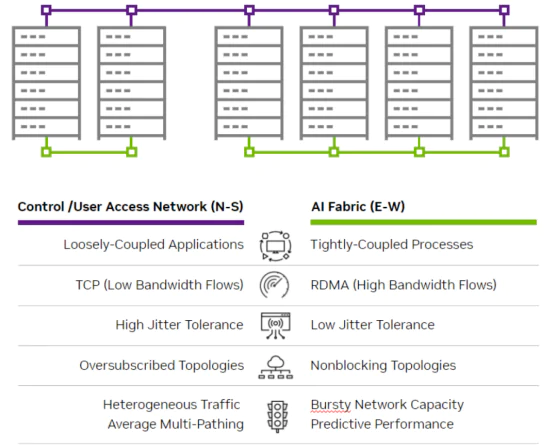
The Spectrum-X solution is primarily positioned to address the east-west traffic within AI Cloud, which encompasses the substantial computational traffic generated by GPU training and
inference. It is specifically designed for tight coupling, necessitating a lossless network with RDMA support, low jitter, minimized tail latency, and a high-speed, non-blocking network
capable of accommodating the transient burst traffic resulting from many-to-one communication patterns. However, the north-south traffic is still entrusted to traditional Ethernet networks,
providing support for multi-tenant isolation and management, as well as distributed storage networks.
(2) Adaptive Routing
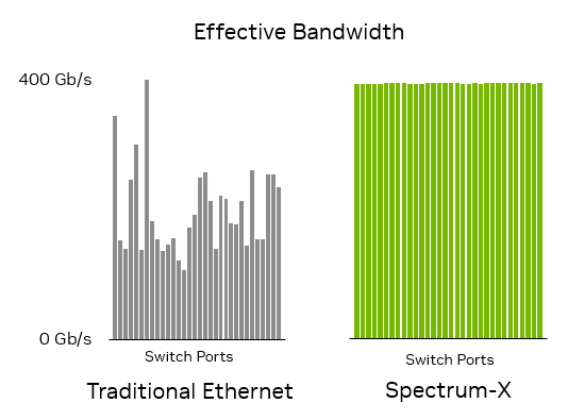
This feature can be described as a killer feature within the Spectrum-X solution. It tackles the problem of uneven ECMP (Equal-Cost Multipath) bandwidth caused by static hashing in
traditional Ethernet networks. Through tight coupling and coordination between the network-side switches and endpoint DPUs, Spectrum-X enables real-time dynamic monitoring of the
physical bandwidth of each ECMP link and the congestion situation at the port egress. This allows for dynamic load balancing on a per-packet basis, increasing the link bandwidth utilization
from the typical 50-60% range in regular Ethernet networks to over 97%.
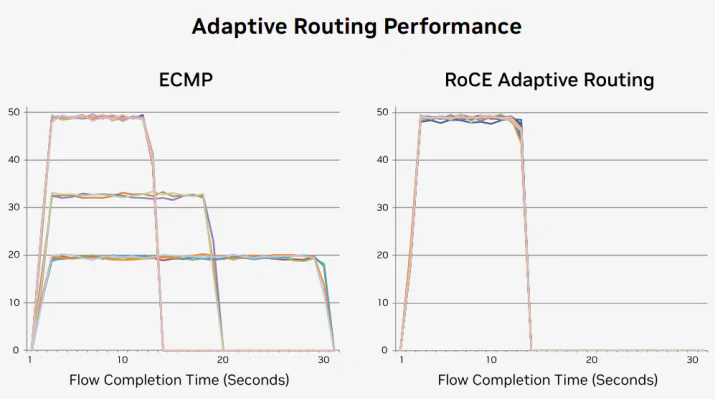
By increasing the utilization of link bandwidth, the Spectrum-X solution aims to mitigate the long tail latency caused by congestion from various large-scale flows in AI applications, as
depicted in the diagram above. In ECMP scenarios, unequal utilization of link bandwidth can lead to significantly increased completion times for certain flows. However, adaptive routing can
evenly distribute the flows across all available links, significantly reducing transmission times for each flow and achieving a more balanced distribution. This, in turn, decreases the
completion time for each training task.
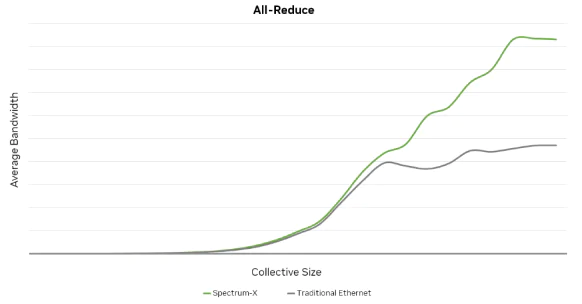
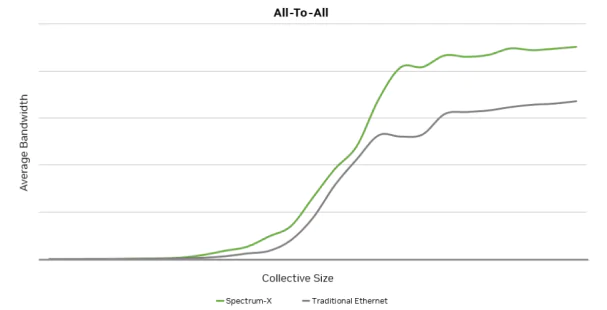
As a result of effectively increasing link bandwidth utilization, the Spectrum-X solution demonstrates substantial improvements over traditional Ethernet networks for typical traffic models in
AI training, such as All-Reduce and Al-to-All. The impact becomes more pronounced as the message size for collective communication grows larger.
(3) Direct Data Placement
Although per-packet load balancing can greatly enhance bandwidth utilization, it brings forth a significant issue of packet reordering at the receiving end. Several vendors have similar
solutions, some tackling it through network-side approaches while others rely on endpoint-side resolutions. However, due to hardware performance limitations, there hasn’t been a relatively
satisfactory solution thus far. Spectrum-X, leveraging the hardware collaboration of Spectrum4 switch on the network side and BF3 on the endpoint side, perfectly addresses this problem.
Let’s examine the process of RoCE packet reordering in the diagram below.
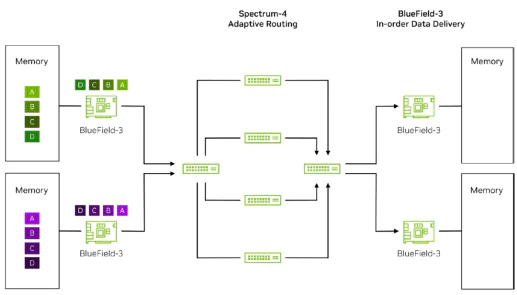
Firstly, on the left-hand side, we can see that the training traffic generated from various GPU memories is marked by their respective sending-side BF3 network cards and sent to the directly
connected TOR Spectrum-4 switch.
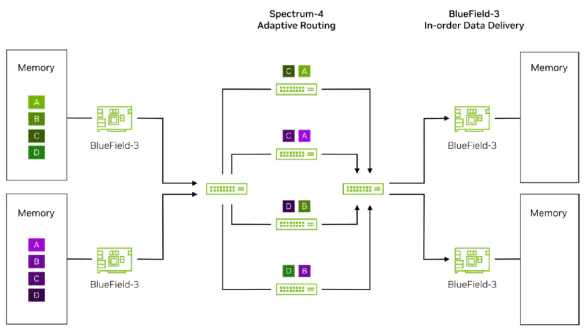
Next, the TOR switch hardware recognizes the packets marked by BF3 and performs adaptive routing based on the real-time bandwidth and buffer status of the upstream links. It evenly
distributes the packets of each flow in a per-packet manner across the upstream links, which means they are delivered to the four Spine switches.
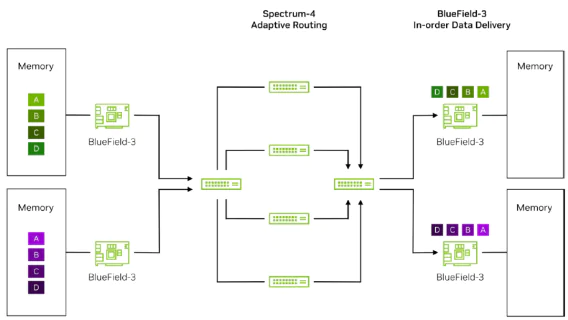
The packets pass through their respective Spine switches and arrive at the destination-side TOR switch before ultimately reaching the BF3 network card of the destination server. At this point,
the packets may be subject to potential packet reordering.
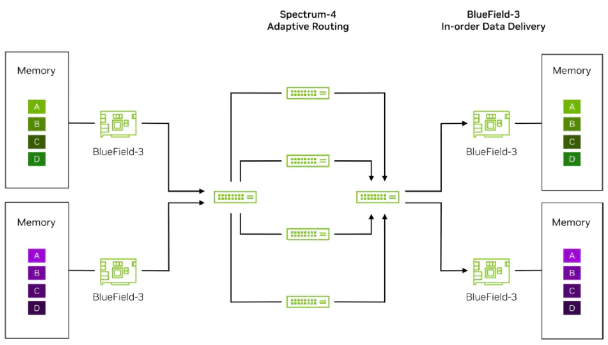
The destination BF3 network card recognizes the packets marked by the sending-side BF3 through hardware. It then utilizes DDP (Direct Data Placement) technology to read the memory
addresses of the packets and directly places them into the memory of the destination GPU. This process ensures that the packets are assembled into an ordered packet sequence, eliminating
the packet reordering caused by different network paths and devices. By combining the synergistic hardware acceleration technologies of adaptive routing and DDP, it perfectly solves the
issues of uneven bandwidth in traditional Ethernet ECMP and packet reordering. It also alleviates the long-tail latency problems caused by packet reordering in certain applications.
(4) Multi-Tenant Performance Isolation
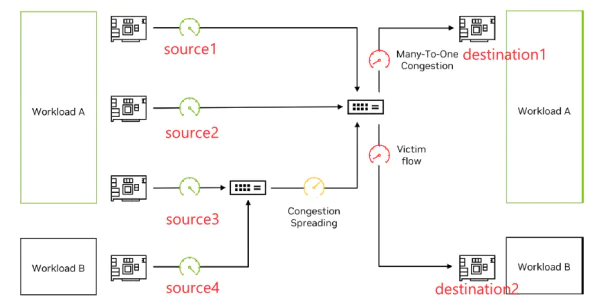
In a multi-tenant or multi-tasking scenario within a RoCE network, it is relatively easy to achieve isolation using technologies like VXLAN. However, ensuring performance isolation
between different tenants or tasks has always been a challenging problem. Some applications that perform well in a physical bare-metal environment fail to achieve the same level of
performance in a cloud environment. For instance, in the above diagram, there are two types of tenant traffic: workload A and workload B. In workload A, a congestion event occurs with a 3-
to-1 ratio, triggering congestion control mechanisms and causing sources 1-3 to reduce their speeds to one-third of the bandwidth. However, since source 3 and source 4 share the same switch
egress, the congestion control command also propagates to source 4, resulting in source 4 being throttled to one-third of its bandwidth. Consequently, the workload B traffic from source 4 to
destination 2, which should have enjoyed two-thirds of the bandwidth, becomes a victim flow. In the AI cloud world, where every inch of space is valuable, no tenant wants to be the victim
flow and they all desire to achieve performance similar to the physical AI world.
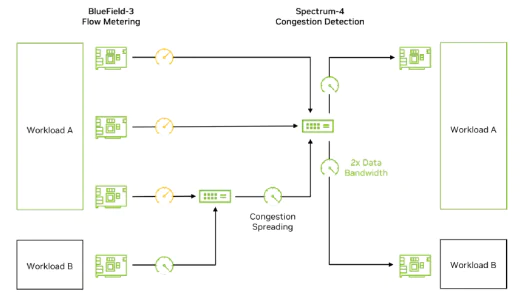
Spectrum-X utilizes the powerful programmable congestion control hardware on BF3 to offer a congestion control algorithm that outperforms traditional DCQCN (Data Center Quantized
Congestion Notification). The sending-side and receiving-side BF3 collaboratively send RTT (Round-Trip Time) probe packets using hardware. At the same time, they incorporate inband
telemetry information from intermediate switches, which includes details such as timestamps of packet traversal through the switch and egress buffer utilization. This combined information
enables accurate assessment of congestion conditions along the paths taken by each flow. Moreover, BF3’s hardware can process millions of congestion control packets per second, effectively
achieving congestion control based on different workloads and ensuring performance isolation. With the performance isolation between workload A and workload B, the path from source 4 to
destination 2 can fully utilize two-thirds of the bandwidth.
(5) Direct Drive Optical Module
Both Spectrum-4 switches and BF3 utilize NVIDIA’s in-house developed 100Gbps PAM4 SerDes technology. They employ Direct Drive LPO (Laser Power Optimization) technology to
directly connect the SerDes of the optical modules to the Spectrum-4 ASIC chip, eliminating the need for DSP or CDR components in the optical modules. This approach significantly
reduces the power consumption of the optical modules, bringing the power consumption of 400G and 800G optical modules down to single-digit values from over ten watts. This results in a
noticeable reduction in overall power consumption for switches and DPUs equipped with fully populated 400G optical modules.
(6) Full-stack end-to-end software optimization
The aforementioned advantages primarily stem from the hardware-level acceleration provided by Spectrum-X. However, this solution also offers various software-level features. For instance,
it provides a visualization and intelligent network management software called NetQ, which allows for monitoring of end-to-end AI traffic. NetQ enables monitoring of RoCE traffic from
both a local perspective and a global network perspective.
(7) ISRAEL-1

To demonstrate the capability of the Spectrum-X solution in supporting large-scale AI compute clusters, Mr. Huang also announced the establishment of an AI Cloud mega-cluster in Israel
named “israel-1” by the end of the year. Just like when the A100 was first introduced, NVIDIA built a 4,000-GPU cluster called “Selene” with InfiniBand, which served as a validation
platform for the Superpod networking architecture and provided an experimental environment for training various large models. The israel-1 cluster will primarily utilize the Spectrum-X
400G solution, including 256 custom Dell HGX H100 servers, totaling 2,048 H100 80G GPUs, 2,560 BF3 DPUs, and over 80 Spectrum-4 Ethernet switches. Each HGX server is expected to
feature 2 BF3 chips for north-south management and storage, and 8 BF3 chips for east-west large-scale AI computing. As both the Spectrum chips and BF3 originate from the Mellanox R&D
team in Israel, which NVIDIA acquired, this AI cluster can be considered a “dream factory” for future massive AI Cloud deployments. It is anticipated that more end-to-end optimization
solutions for AI Cloud will be introduced in the future.
3. Where to Buy NVIDIA Spectrum-X Product fast?
(1) SN5600 Switch

The Spectrum-4 is a 51.2Tbps single-chip 2U box switch that features 100 billion transistors and utilizes TSMC’s 4nm technology. The chip supports 64 800G OSFP ports and can
accommodate a maximum of 128 400G interfaces or 256 200G interfaces. It offers a maximum packet forwarding rate of 33.3 billion packets per second (Bpps) and supports 512K
forwarding table entries. The switch has a buffer cache of 160MB and can achieve line-rate performance for packets as small as 172 bytes. It supports operating systems such as Cumulus and
Sonic. With each generation from Spectrum-1 to Spectrum-4, an increasing number of features have been added:
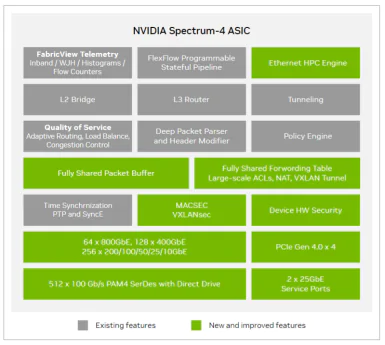
(2) BlueField-3 DPU

The ConnectX-7 ASIC chip features 16 64-bit A78 Arm cores and has a maximum capacity of 400Gbps. It incorporates an independent acceleration processing engine, a programmable
hardware module called DPA, and supports DPDK with a maximum capacity of 267 million packets per second (Mpps). It also supports RDMA with a maximum capacity of 370 Mpps and
offers offloading, isolation, and acceleration capabilities for networking, security, and storage domains. Currently, BF3 is available with two 200G ports and a single 400G port, supporting
both Ethernet and InfiniBand modes simultaneously.
(3) LinkX Cables

In terms of cables, it primarily supports 4x100G PAM4 connections for end-to-end 400G connectivity. It is compatible with the OSFP and QSFP112 MSA standards, covering various form
factors including DAC, ACC, multi-mode, and single-mode optical modules. As shown in the diagram above, the switch’s 800G OSFP port can support a 1-to-2 configuration for 400G OSFP
ports.
4. 800G OSFP Optical Module 2xSR4
To complement the use of the switch, PNA Fiber has introduced the OSFP-800G-2xSR4H module. Please refer to the diagram below:

This module is a dual-port OSFP optical module designed for both InfiniBand and Ethernet. It uses two MPO-12/APC jumpers to connect to other devices, and each port operates at a speed of
400Gb/s. The dual-port configuration is a key innovation that incorporates two internal transceiver engines, fully leveraging the switch’s potential and enabling the 32 physical interfaces to
provide up to 64 400G NDR interfaces. This high-density and high-bandwidth design allows data centers to meet the growing network demands and requirements of applications such as
high-performance computing, artificial intelligence, and cloud infrastructure.
The OSFP 800G 2xSR4H optical module offered by PNA Fiber delivers high performance and reliability, providing a robust optical interconnect solution for data centers. It enables data
centers to fully unleash the performance potential of NVIDIA switches and achieve high-bandwidth, low-latency data transmission.
SUMMERY
Spectrum-X is the world’s first complete end-to-end solution for AI Ethernet, introduced by NVIDIA. It features the Spectrum-4 ASIC switch, BlueField DPU intelligent network card, Direct
Drive-supported Link-X optical module cables, and other powerful hardware components developed by NVIDIA. It combines adaptive routing, endpoint reordering, next-generation
programmable congestion control algorithms, DOCA 2.0, and full-stack AI software acceleration to provide users in the generative AI field with a powerful combination of hardware and
software capabilities. The goal is to expand into the vast Ethernet market with a focus on AI Cloud, bridging the gap between traditional Ethernet and InfiniBand.