How do they Jointly Creating an Intelligent Era?
In the era of digital transformation, the convergence of optical transceivers and artificial intelligence (AI) is revolutionizing various industries. Optical transceivers, which enable high-speed data transmission over optical fibers, and AI, which empowers machines to learn and make intelligent decisions, are joining forces to create a new era of intelligence. In this article, we will explore the synergies between optical transceivers and AI and the transformative impact they have on different sectors.
Enhancing Network Performance:
Optical transceivers play a crucial role in enabling high-speed and reliable data transmission in modern networks. By leveraging AI algorithms, network operators can optimize the performance of optical transceivers. AI can analyze real-time network data, identify bottlenecks, and dynamically adjust the parameters of transceivers to maximize efficiency and minimize latency. This integration of AI and optical transceivers leads to enhanced network performance and improved user experiences.
Intelligent Fault Detection and Predictive Maintenance:
AI-powered analytics can monitor the performance of optical transceivers in real-time, detecting potential faults or anomalies. By analyzing data patterns and historical information, AI algorithms can predict potential failures and proactively initiate maintenance actions. This predictive approach reduces downtime, increases network reliability, and saves costs by avoiding catastrophic failures.
Autonomous Network Management:
The combination of optical transceivers and AI enables autonomous network management. AI algorithms can analyze vast amounts of network data, identify patterns, and make intelligent decisions to optimize network resources. This autonomous management leads to more efficient utilization of bandwidth, dynamic traffic routing, and self-healing capabilities, ensuring uninterrupted connectivity and improved network resilience.
Intelligent Data Center Operations:
In data centers, optical transceivers are critical for high-speed connectivity between servers, storage systems, and networking equipment. By integrating AI into data center operations, optical transceivers can be intelligently managed. AI algorithms can monitor data center traffic, predict peak loads, and dynamically allocate resources to ensure optimal performance and energy efficiency. This intelligent management of optical transceivers in data centers enables better resource utilization and cost savings.
Enabling Intelligent Applications:
The combination of optical transceivers and AI opens up new possibilities for intelligent applications across various industries. From autonomous vehicles to smart cities, AI-powered systems can leverage high-speed data transmission facilitated by optical transceivers to enable real-time decision-making, enhance automation, and improve efficiency. This integration paves the way for the development of innovative solutions that transform industries and improve the quality of life.
Conclusion:
The integration of optical transceivers and artificial intelligence is driving a new era of intelligence across industries. By leveraging AI algorithms, optical transceivers can be intelligently managed, leading to enhanced network performance, proactive fault detection, autonomous network management, and intelligent data center operations. Moreover, this integration enables the development of intelligent applications that revolutionize various sectors. As we move forward, the collaboration between optical transceivers and AI will continue to shape a more intelligent and connected world.
More Over
First, we will explore the AI revolution initiated by ChatGPT and the explosive demand for computing power, which has become the main driving force behind the optical transceiver market. In the second part, we will use NVIDIA computers and the GPT-3 large model as examples for calculation.
AI Large Models Drive Demand for Computing Power
The emergence of ChatGPT leads the AI wave. ChatGPT is an artificial intelligence (AI) conversational chatbot software (model) released by the American startup company OpenAI. It is a large-scale language model (LLM) based on the GPT-3.5 architecture. It can perform tasks such as writing emails, code, translation, and provide broader search services. Subsequently, an AI arms race ensued, significantly boosting the demand for computing power. Currently, several large AI models have appeared in China, such as Tencent’s Mixnet, Baidu’s Wenxin, Peng Cheng Laboratory’s Pangu, the Purple East Tai Chu model developed by the Institute of Automation of the Chinese Academy of Sciences, and Alibaba’s AI pre-training model M6. The number of large language models is expected to continue to increase in the future.
Specifically, AI large models can be divided into the training side and the inference side. The training process, also known as the learning process, involves training a complex neural network model through large amounts of data. This process determines the values of the weights and biases in the network, enabling it to adapt to specific functions. The training process requires high computational performance and a massive amount of data, and the trained network has a certain degree of generality.
The inference process, also known as the decision-making process, utilizes the trained model and the predetermined parameters of the neural network to perform calculations and draw various conclusions using new data. The influencing factors of the training process of large models mainly include the number of model parameters, the amount of training data, and the chip’s computing power.
Regarding the number of model parameters, according to Wave Computing’s “AI Computing Cluster Solution Design and Optimization,” the parameter count of large models has increased from 94 million in the past four years to 530 billion, nearly a 5600-fold growth. The computing power chip is mainly provided by NVIDIA GPUs, which are used in supercomputers corresponding to optical transceivers. NVIDIA’s AI GPUs include A100 and H100, and the newly launched supercomputer DGX GH200 at the end of May is equipped with their super chip, Grace Hopper. Grace Hopper combines the NVIDIA Hopper GPU with the NVIDIA Grace CPU, and the NVIDIA NVLINK-C2C used provides a total bandwidth of 900 Gb/s, greatly increasing the demand for optical transceivers in supercomputers.
In addition, cloud vendors’ 2022 performance exceeded expectations, and NVIDIA’s data center revenue reached a historic high, mainly benefiting from the increased demand for GPU chips in training AI from cloud and enterprise customers, further signaling positive trends. With the continuous introduction of large AI models and increased investment in AI training by cloud vendors both domestically and internationally, high growth certainty will be further extended.

Predicting the NVIDIA Computers: Significantly Increased Demand for 800G Optical Transceivers
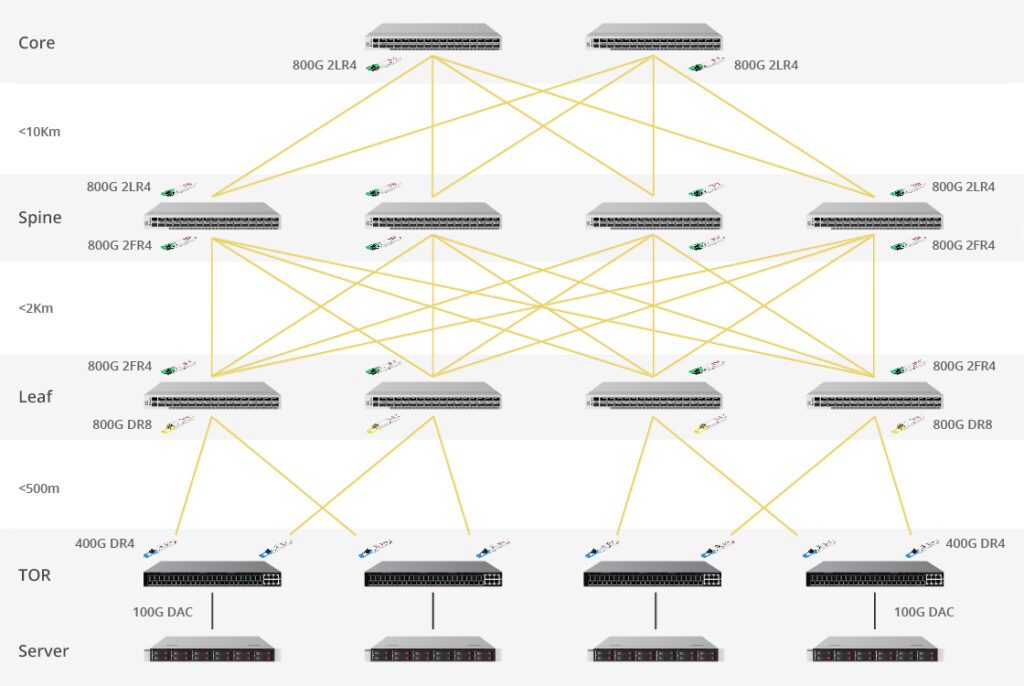
First, let’s use the NVIDIA DGX SuperPOD as an example to calculate the ratio between a single GPU and optical transceivers. The DGX A100 and DGX H100 network clusters mainly use two types of networks: InfiniBand and Ethernet. They can be divided into four categories based on network functions: computation, storage, InBand, and Out-of-Band. Among them, InfiniBand is used for AI operations and storage, making it the main source of demand for optical transceivers. Ethernet has relatively lower demand. Therefore, the following calculations only consider the optical transceiver demand corresponding to the InfiniBand network.
Taking a DGX A100 cluster with 140 nodes as an example, each DGX A100 server requires 8 A100 GPU chips, totaling 140 * 8 = 1120 chips. The cluster consists of 7 scalable units (SUs), with each SU composed of 20 DGX A100 servers. On the computing side, a three-layer switch fat-tree topology is used. The first to third layers are referred to as Leaf switches, Spine switches, and Core switches, respectively. Under the InfiniBand network architecture, a complete fat-tree topology is implemented. The optimal configuration for a Fat-Tree architecture in training scenarios is to have an equal number of uplink and downlink ports, creating a non-blocking network. Specifically:
- First layer: Each SU is equipped with 8 Leaf switches, totaling 56 Leaf switches.
- Second layer: Every 10 Spine switches form a Spine Group (SG). The first Leaf switch of each SU is connected to each switch in SG1, and the second Leaf switch of each SU is connected to each switch in SG2. There are a total of 80 Spine switches.
- Third layer: Every 14 Core switches form a Core Group (CG), resulting in a total of 28 Core switches.
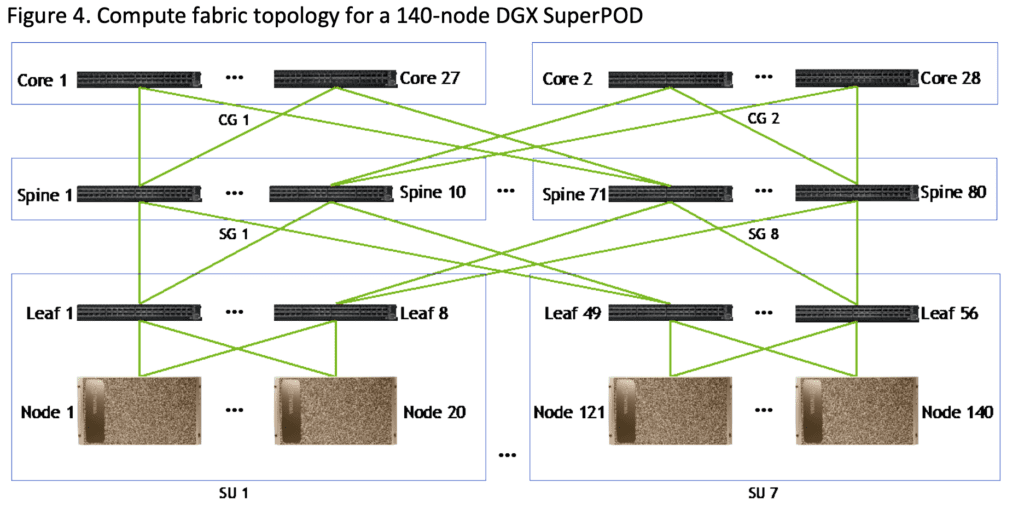
Considering the A100 system used in the NVIDIA DGX SuperPOD whitepaper, both the computing side and storage side cables are all using NVIDIAMF1S00-HxxxE, which are 200G HDR AOC active optical cables. Therefore, each port corresponds to one optical transceiver, meaning that each cable requires 2 optical transceivers. As a result, the computing side and storage side require a total of (1120+1124+1120)*2 + (280+92+288)*2 = 8048 optical modules. This means that the approximate ratio of the required 200G optical transceivers to a single GPU is 1:7.2.
On May 29th, NVIDIA released the latest DGX GH200 supercomputer, which is equipped with 256 NVIDIA GH200 Grace Hopper super chips. Each super chip can be seen as a server, interconnected through NVLINK SWITCH. Structurally, the DGX GH200 adopts a two-layer fat-tree topology, with 96 and 36 switches in the first and second layers, respectively.
Each NVLINK SWITCH has 32 ports with a speed of 800G. In addition, the DGX GH200 is equipped with 24 NVIDIA Quantum-2 QM9700 IB switches for the IB network. Based on port estimation, assuming that the L1 layer is connected with copper cables and does not involve optical transceivers, and considering the non-blocking fat-tree architecture, the 36 switches in the L2 layer have their ports connected to the uplink ports of the L1 layer switches.
Therefore, a total of 36 * 32 * 2=1152 optical transceivers are required. Under the IB network architecture, the 24 switches require 24 * 32 = 768 800G optical transceivers. Therefore, the DGX GH200 supercomputer requires a total of 1152 + 768 = 1920 800G optical transceivers, corresponding to 12 800G optical transceivers per GH200 chip. This represents a significant increase in the number and speed of optical transceivers compared to the DGX SuperPOD.
Let’s calculate the increase in the number of optical transceivers brought about by large language models in both the training and inference sides.
On Training Side
Taking GPT-3 as an example, the unit of measurement for computational power is FLOPs (floating-point operations). According to OpenAI’s paper “Language Models are Few-Shot Learners”, training the largest model in GPT-3 (with 1.746 trillion parameters) requires approximately 3.14 * 10^23 FLOPs.
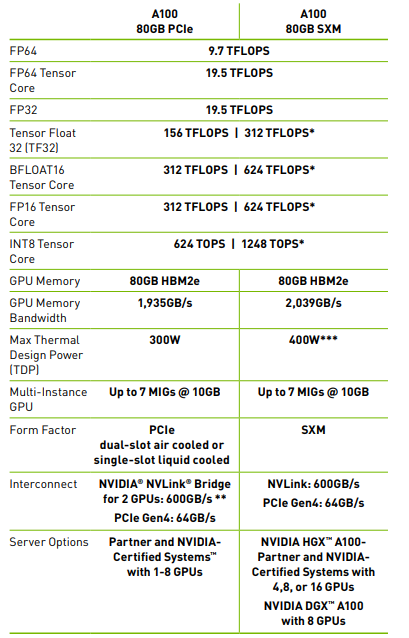
When training a large model using NVIDIA A100 GPUs, training can be done using FP16 precision, which corresponds to 312 TFLOPS (312 trillion floating-point operations per second). Based on the total computational workload = number of GPUs * GPU performance * training time, the number of GPUs can be calculated as GPUs = total computational workload / (GPU performance * training time).
Assuming a training time of 1 day, GPT-3 would require approximately 3.14 * 10^23 FLOPs / (312 * 10^12 FLOPs/s * 86400s), which is about 11,648 GPUs. In the case of a 10-day training period, it would require 3.14 * 10^23 FLOPs / (312 * 10^12 FLOPs/s * 86400s * 10) = 1,165 GPUs.
Based on the previous estimation that each A100 GPU requires 7 200G optical transceivers in the system, GPT-3 would require over 80,000 200G optical transceivers to complete training in a single day. Taking into account the utilization rate of FLOPS, which is around 20%-30%, the required number of optical transceivers would be around 350,000.
Currently, the number of large language models is rapidly increasing. According to incomplete statistics, as of now, there have been 79 domestically released large models with over 1 billion parameters. At the same time, the parameter count is increasing rapidly, reaching trillions or more. This will also lead to a significant increase in demand for computing power and optical transceivers.
Inference Side
Currently, large language models are in a rapid development phase, with a focus on the training side. However, once large models mature, the main demand for optical transceivers will shift to the inference side. The quantity of optical transceivers on the inference side can be calculated based on user traffic.
Under an optimistic estimate, assuming a daily traffic volume of 1 billion for ChatGPT in a stable state, with each ChatGPT response consisting of 1000 characters (roughly equivalent to 1000 tokens, assuming a 1:1 ratio between tokens and Chinese characters), this amounts to a total of 1 trillion tokens. Assuming the use of GPT-3 as the large model for inference, according to the “Scaling Laws for Neural Language Models,” the ratio of FLOPs per parameter per token is 6 during training and approximately 2 during inference. Therefore, the computational power required for one inference is 2 * 1 trillion * 1.746 trillion, totaling 3.5 * 10^23 FLOPs. Since the computational power requirements during inference are relatively lower than during training, using A100 chips may be cost-inefficient and have insufficient memory.
Therefore, A30 or even A10 chips can be used for inference. Based on A30’s computational power, the calculation method for the demand is the same, resulting in approximately 25,000 GPUs. Taking into account the utilization rate of FLOPs, which is around 20%-30%, the required number of GPUs would be around 130,000. Similarly, assuming a trillion-scale large model based on the GPT-3 framework, the inference side would require approximately 800,000 GPUs using A30’s computational power, corresponding to millions of optical transceivers.
Under a neutral estimate, with a daily traffic volume of 500 million for ChatGPT in a stable state, and under a pessimistic estimate, with a daily traffic volume of 100 million for ChatGPT in a stable state, the corresponding number of GPUs would be 400,000/80,000, and the corresponding number of optical transceivers would be over a million under the neutral estimate and close to a million under the pessimistic estimate.
In conclusion, optical transceivers play a crucial role in driving the AI revolution and large-scale model computations. As a leading provider of comprehensive optical transceiver solutions, PNA Fiber is committed to building an interconnected and intelligent world with innovative computing and networking solutions. We look forward to witnessing further breakthroughs and innovations in optical transceiver technology in the future, providing stronger support for AI and big data applications, and driving technological progress and social development.