1. ChatGPT Triggers AI Wave, Cloud Computing Enters the Fast Development

The remarkable success of ChatGPT has brought significant attention to the advancements in artificial intelligence. ChatGPT showcases its impressive capabilities not only in everyday conversations, answering professional queries, retrieving information, generating content, creating literature, and composing music but also in code generation and debugging, as well as providing code annotations.
The user base of ChatGPT continues to skyrocket. Within just two months of its launch, ChatGPT surpassed 100 million monthly active users, making it the fastest-growing consumer application in history.
The operation of ChatGPT requires powerful cloud computing resources. The GPT model, initially released by OpenAI in 2018, had 117 million parameters and was trained on approximately 5GB of pretraining data. In contrast, GPT-3 boasts a staggering 175 billion parameters and was trained on 45TB of data. During the model training phase alone, ChatGPT consumed around 3640 PF-days of computing power, with a training cost of 12 million USD. The operational phase incurs even higher resource consumption. To handle the search and access demands of current ChatGPT users, an estimated initial investment of approximately 3-4 billion USD in computational infrastructure, utilizing servers (GPUs) for processing, would be required. On the evening of February 7th, ChatGPT experienced another outage due to a surge in traffic, underscoring the immense computational power demand of AI applications reliant on cloud computing.
2. AI May Reshape DataCenter Network Architecture, Leading to a Significant Increase in Demand for Optical Transceivers
AI-Guided Content (AIGC) technologies like ChatGPT, relying on powerful AI models and vast amounts of data, generate high-quality content across various applications, driving the wider adoption of artificial intelligence. Computational power, as one of the crucial pillars supporting AIGC technologies, is a core factor influencing the development and application of AI. The computational infrastructure has become a vital resource that the industry urgently needs to address. In addition to strong demand for computational hardware such as CPUs and GPUs, the network side has also given rise to increased bandwidth requirements to match the growing traffic. Compared to the network architecture of traditional data centers, AI data centers are expected to undergo some changes.
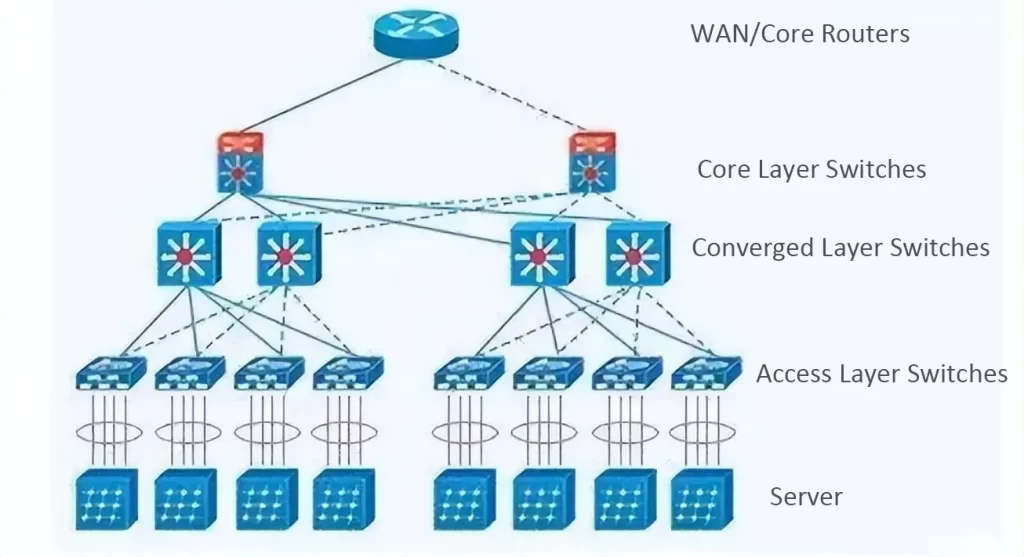
In traditional data centers, the network side mainly consists of traditional hierarchical three-tier architectures and leaf-spine architectures. Early data centers typically adopted the traditional three-tier structure, including the access layer, aggregation layer, and core layer. The access layer connects computing nodes to cabinet switches, the aggregation layer facilitates interconnection between access layers, and the core layer handles interconnection between aggregation layers and external networks. However, with the rapid increase in east-west traffic within data centers, the core and aggregation layers of the three-tier network architecture face increased tasks and higher performance requirements, resulting in significantly higher equipment costs. Therefore, a flat leaf-spine network architecture suitable for east-west traffic has emerged. In this architecture, leaf switches connect directly to compute nodes, while spine switches act as core switches, dynamically selecting multiple paths through Equal-Cost Multipath (ECMP). The leaf-spine network architecture offers advantages such as high bandwidth utilization, good scalability, predictable network latency, and high security, making it widely applicable in data centers.
In AI data centers, due to the large internal data traffic, an unblocked fat-tree network architecture has become an important requirement. NVIDIA’s AI data centers utilize a fat-tree network architecture to achieve the unblocked functionality. The basic concept of a fat-tree network architecture is to use a large number of low-performance switches to construct a massive unblocked network where, for any communication pattern, there are paths that allow the communication bandwidth to reach the bandwidth of the network interface cards (NICs), and all switches used in the architecture are the same. The fat-tree network architecture is commonly used in data centers with high network requirements, such as supercomputing centers and AI data centers.
In NVIDIA’s DGX A100 SuperPOD AI data center system, all three-tier switches are NVIDIA Quantum QM8790 40-port switches. The first-tier switches are connected to 1120 Mellanox HDR 200G InfiniBand NICs. The downlink ports of the second-tier switches are connected to the first-tier switches, while the uplink ports are connected to the third-tier switches. The third-tier switches only have downlink ports and are connected to the second-tier switches. Additionally, the storage side has a separate network architecture separated from the compute side, requiring a certain number of switches and optical transceivers. Therefore, compared to traditional data centers, the number of switches and optical transceivers in AI data centers has significantly increased.
NVIDIA’s A100 GPUs primarily correspond to 200G optical transceivers, while H100 GPUs can correspond to 400G or 800G optical transceivers. Each A100 GPU is equipped with a Mellanox HDR 200Gb/s InfiniBand NIC, and each H100 GPU is equipped with a Mellanox NDR 400Gb/s InfiniBand NIC. In NVIDIA’s H100 SuperPOD design, 800G optical transceivers are used. With one 800G optical transceiver in the optical port, it can replace two 400G optical transceivers, and in the electrical port, eight SerDes channels can be integrated, corresponding to the eight 100G channels in the optical port. Therefore, in this design, the channel density of the switches is increased, and the physical size is significantly reduced.
The rate of optical transceivers is determined by the network cards, and the speed of network cards is limited by the PCIe channel speed. Inside NVIDIA’s A100 DGX servers, they are connected internally via NVLink3 with a unidirectional bandwidth of 300GB/s. However, the A100 GPUs are connected to ConnectX-6 network cards through 16 PCIe 4.0 channels, with a total bandwidth of around 200G. Therefore, the bandwidth of the network card is 200G, requiring a connection to a 200G optical transceiver or DAC cable. In the case of H100 DGX servers, they are internally connected via NVLink4 with a unidirectional bandwidth of 450GB/s. The H100 GPUs are connected to ConnectX-7 network cards through 16 PCIe 5.0 channels, with a total bandwidth of around 400G.
Hence, the bandwidth of an individual network card is 400G. It can be observed that the speed of optical transceivers is determined by the PCIe bandwidth between the network card and the GPU. Assuming that the PCIe channel speed used internally in the A100 and H100 DGX servers reaches 800G (i.e., PCIe 6.0), it would be possible to adopt network cards with an 800G bandwidth and utilize 800G optical transceivers, significantly enhancing the system’s computational efficiency.
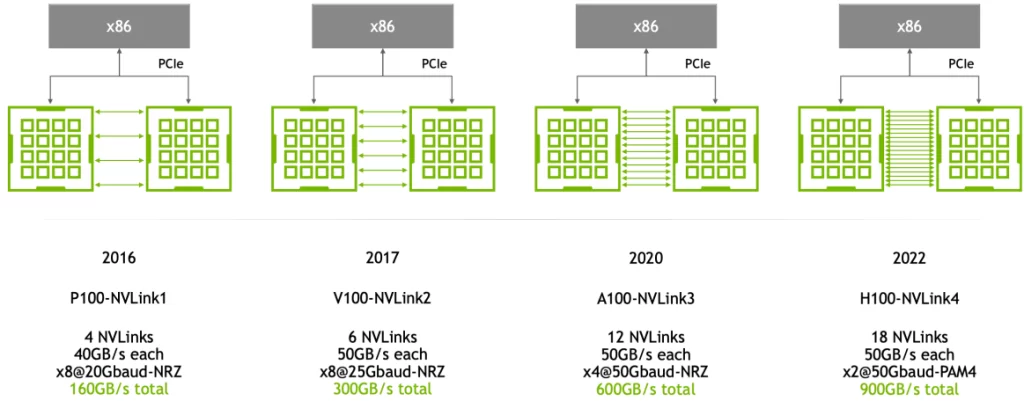
The NVLink bandwidth is much greater than the PCIe bandwidth on the network card side. Therefore, expanding NVLink from GPU interconnect within a server to interconnect between GPUs in different servers will significantly increase the system’s bandwidth. To achieve GPU interconnect between different servers according to the NVLink protocol, it requires physical switches with NVSwitch chips and physical components to connect the switches to the servers. Therefore, optical transceivers also become important components, leading to a significant increase in the demand for 800G optical transceivers.
The demand for optical transceivers on the training side is strongly correlated with GPU shipments, while the demand on the inference side is strongly correlated with data traffic. The increase in demand for optical transceivers in AI can be divided into two stages: training and inference. In the training stage, a fat-tree network architecture is primarily used because high network performance is crucial for large-scale model training. Having an unblocked network is an important requirement. For example, Tencent’s StarNet, used for large-scale model training, adopts a fat-tree network architecture.
At the same time, NVIDIA believes that most vendors will adopt InfiniBand protocol networks, which have lower latency than Ethernet, to improve computational efficiency and reduce model training time. The demand for optical transceivers on the training side is closely related to the number of GPUs used. Based on the ratio of GPUs to optical transceivers in the fat-tree architecture, the required number of optical transceivers can be determined. A100 corresponds to 200G optical transceivers, while H100 corresponds to 400G or 800G optical transceivers.
On the inference side, the network architecture is more similar to the leaf-spine architecture of traditional cloud computing data centers. It is mainly used to handle the increased data traffic generated by AI applications from the user side. Traditional cloud computing primarily serves the B2B market with a relatively small number of users. However, if there is a popular AI application related to images or videos in the future, the user base may significantly increase, and the data traffic generated by each user may also grow significantly. As a result, the overall data traffic will skyrocket, and the computational power and traffic required for inference may actually exceed that of training. Therefore, the demand for network equipment, including optical transceivers, will play a crucial role in supporting and boosting the infrastructure.
3. 800G Optical Transceivers has Arrived, and 2024 May Become the Year of 800G

PNA Fiber is a leading provider of optical network solutions with top-notch capabilities in research and development, manufacturing, and technical services. They have a leading advantage in the production of 800G high-speed optical transceiver products. In 2023, they introduced a new series of 800G optical transceivers and solutions for ultra-large-scale cloud data centers worldwide. The product lineup includes the 800G OSFP DR8+, 800G OSFP 2xFR4, and 800G OSFP DR8 optical transceiver types. These products have gained wide attention from clients and industry professionals due to their excellent quality and performance. Additionally, PNA Fiber also provides 800G and 400G AOC (Active Optical Cables) and DAC (Direct Attach Cables) high-speed cable products for customers in various industries, continuously offering innovative, efficient, and reliable optical network products, solutions, and services.
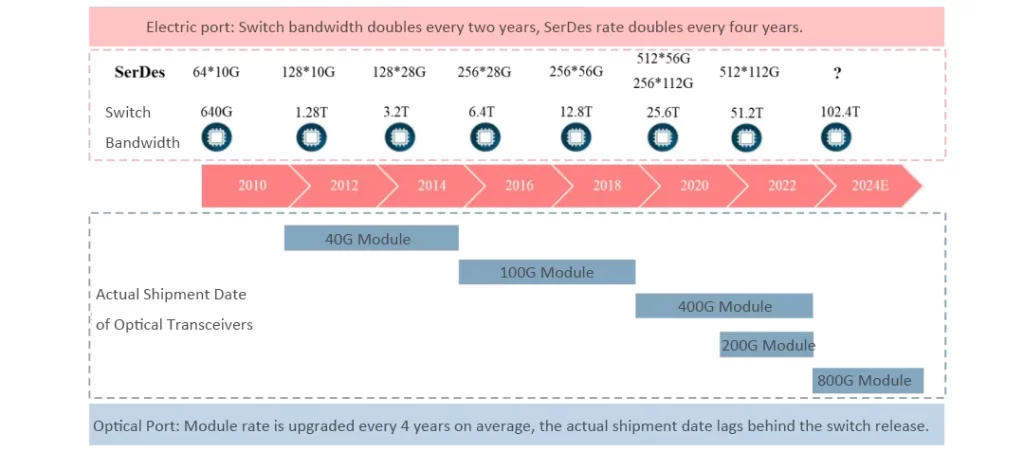
Looking at the electrical ports of switches, the SerDes channel rate doubles every four years, the quantity doubles every two years, and the switch bandwidth doubles every two years. In terms of optical ports, the upgrade cycle for optical transceivers is approximately every four years, and the actual shipping time is later than the release of new versions of SerDes and switch chips. In 2019, as the time point for upgrading to 100G optical transceivers, the market was divided into two upgrade paths: 200G and 400G. However, by 2023, the next generation of high-speed optical transceivers in the market are all targeting 800G optical transceivers. Coupled with the increasing computational power and model competitions brought by AI and GC (Generalized Convolutional) networks, it is expected that major cloud providers and technology giants in North America will likely make significant purchases of 800G optical transceivers in 2024, and possibly even in 2023.
In the context of the development of large-scale artificial intelligence models, the demand for 800G optical transceivers is expected to rapidly increase. With the exponential growth in AI computational power requirements, there is a need for optical transceivers with faster transmission speeds and higher coverage. PNA Fiber will provide the industry with higher-speed, higher-quality 800G optical transceiver solutions. Leveraging their deep technical expertise and extensive project experience in the fields of optical networking and high-performance computing, they will continue to deliver excellent products, solutions, and technical services for data centers, high-performance computing, edge computing, artificial intelligence, and other application scenarios. Together, we can create a connected world of intelligent data.