Provide one-stop FTTH products and solutions since 2008 year
What’s the network requirements for AI Large-Scale Models in Data Centers?
Table of Contents
Since the advent of Transformers until the popularity of ChatGPT in 2023, people have gradually realized that as the model’s parameter size increases, the model’s performance improves, and there is a scaling law that governs their relationship. Furthermore, when the model’s parameter size exceeds several hundred billion, the language understanding, logical reasoning, and problem analysis capabilities of AI large models rapidly improve. Along with the increase in model size and performance, the requirements for network in AI large model training have also changed compared to traditional models.
To meet the efficient distributed computing requirements of large-scale training clusters, AI large model training processes typically include various parallel computing modes such as data parallelism, pipeline parallelism, and tensor parallelism. In different parallel modes, collective communication operations are required among multiple computing devices. Additionally, the training process usually adopts a synchronous mode, where collective communication operations among multiple machines and multiple cards must be completed before the next iteration or computation of training can proceed. Therefore, in large-scale training clusters of AI large models, designing an efficient cluster networking scheme to achieve low latency and high throughput inter-machine communication is crucial for reducing the communication overhead of data synchronization among multiple machines and cards, and improving the GPU’s effective computation time ratio (GPU computation time / overall training time). This efficiency improvement is essential for AI distributed training clusters. The following analysis will examine the requirements of AI large models on networks from the perspectives of scale, bandwidth, latency, stability, and network deployment.
1. Ultra-Large-Scale Networking Requirements
The computational demand of AI applications is growing exponentially, and algorithmic models are evolving towards massive scales. The parameters of artificial intelligence models have increased by a factor of a hundred thousand in the past decade, and current AI large models have reached parameter sizes in the range of hundreds of billions to trillions. Training such models undoubtedly requires high computational power. Additionally, ultra-large models have high requirements for memory. For example, a 1 trillion parameter model using 16-bit precision storage would consume 2 terabytes of storage space. Furthermore, during the training process, intermediate variables generated by forward computation, gradients generated by backward computation, and optimizer states required for parameter updates all need to be stored, and these intermediate variables also increase continuously within a single iteration. A training process using the Adam optimizer produces intermediate variables that peak at seven times the size of the model parameters. Such high memory consumption means that dozens to hundreds of GPUs are needed to store the complete training process of a model.
However, having a large number of GPUs alone is still insufficient to train effective large models. The key to improving training efficiency lies in adopting suitable parallelization methods. Currently, there are three main parallelization methods for ultra-large models: data parallelism, pipeline parallelism, and tensor parallelism. All three parallelization methods are used in the training of models in the range of hundreds of billions to trillions of parameters. Training ultra-large models requires clusters consisting of thousands of GPUs. At first glance, this scale may seem inferior compared to the interconnection scale of tens of thousands of servers in cloud data centers. However, in reality, interconnecting thousands of GPU nodes is more challenging because network capabilities and computational capabilities need to be highly matched. Cloud data centers use CPU computation, and their network requirements typically range from 10 Gbps to 100 Gbps, using traditional TCP transport layer protocols. On the other hand, AI large model training utilizes GPU training, which has computational power several orders of magnitude higher than CPUs. Therefore, the network demands range from 100 Gbps to 400 Gbps, and RDMA protocols are used to reduce transmission latency and improve network throughput.
Specifically, the high-performance interconnection of thousands of GPUs poses several challenges in terms of network scale:
Issues encountered in large-scale RDMA networks, such as head-of-line blocking and PFC deadlock storms.
Network performance optimization, including more efficient congestion control and load balancing techniques.
Network card connectivity issues, as a single host is subject to hardware performance limitations.How to build thousands of RDMA QP connections?
Network topology selection, whether the traditional Fat Tree structure is better or if reference can be made to high-performance computing network topologies such as Torus and Dragonfly.
2. Ultra-High Bandwidth Requirements
In the scenario of AI large-scale model training, the collective communication operations between GPUs within and across machines generate a large amount of communication data. From the perspective of GPU communication within the machine, taking AI models with billions of parameters as an example, the collective communication data generated by model parallelism will reach the scale of hundreds of gigabytes. Therefore, the communication bandwidth and mode between GPUs within the machine are crucial for achieving efficient completion time. The GPUs inside the server should support high-speed interconnection protocols, and this further avoids the need for multiple copies of data through CPU memory during GPU communication. From the perspective of GPU communication across machines, different communication operations are required for pipeline parallelism, data parallelism, and tensor parallelism modes.
Some collective communication data will reach the scale of hundreds of gigabytes, and complex collective communication patterns will generate one-to-many and many-to-one communications at the same time. Therefore, high-speed interconnection of GPUs across machines imposes high requirements on the single-port bandwidth of the network, the number of available links between nodes, and the overall network bandwidth.
Additionally, GPUs are typically connected to network cards via PCIe bus, and the communication bandwidth of the PCIe bus determines whether the single-port bandwidth of the network card can be fully utilized. Taking PCIe 3.0 bus as an example (16 lanes corresponding to a unidirectional bandwidth of 16GB/s), when the inter-machine communication is equipped with a single-port bandwidth of 200Gbps, the network performance between machines cannot be fully utilized.
3. Ultra-Low Latency and Jitter Requirements
The network latency generated during data communication consists of two components: static latency and dynamic latency. Static latency includes data serialization latency, device forwarding latency, and electro-optical transmission latency. Static latency is determined by the capabilities of the forwarding chip and the transmission distance. When the network topology and communication data volume are fixed, this part of the latency is usually a constant value. The dynamic latency, on the other hand, has a significant impact on network performance. Dynamic latency includes queuing latency within switches and latency caused by packet loss and retransmission, which are usually caused by network congestion and packet loss.
Taking the training of GPT-3 model with 175 billion parameters as an example, theoretical analysis of the model suggests that when the dynamic latency increases from 10μs to 1000μs, the proportion of effective GPU computing time will be reduced by nearly 10%. When the network packet loss rate is one in a thousand, the proportion of effective GPU computing time will decrease by 13%. When the network packet loss rate reaches 1%, the proportion of effective GPU computing time will be less than 5%. Reducing computational communication latency and improving network throughput are crucial issues for fully harnessing the computational power in AI large-scale model training.
In addition to latency, latency jitter introduced by network variations also affects training efficiency. The collective communication process of computing nodes during training can generally be decomposed into multiple parallel P2P communications between nodes. For example, the Ring AllReduce collective communication between N nodes involves 2\*(N-1) data communication substeps, where all nodes in each substep must complete P2P communication (in parallel) for the substep to be completed. When there is network fluctuation, the flow completion time (FCT) of P2P communication between two specific nodes will noticeably increase. The variation in P2P communication time caused by network jitter can be seen as the weakest link in the efficiency of the system, leading to an increase in the completion time of the corresponding substep. Therefore, network jitter reduces the efficiency of collective communication, thereby affecting the training efficiency of AI large-scale models.
Since the advent of Transformers, it has marked the prologue of rapid evolution in large-scale models. In the past five years, the model size has grown from 61 million to 540 billion, an increase of nearly 10,000 times! The computational power of the cluster determines the speed of AI model training. Training GPT-3 on a single V100 GPU would take 335 years, while a cluster of 10,000 V100 GPUs would ideally scale linearly and complete training in approximately 12 days.
The availability of the network system is fundamental to determining the computational stability of the entire cluster. On one hand, network failures can have a broad impact, as a network node failure in the cluster can disrupt the connectivity of dozens or even more compute nodes, thereby compromising the integrity of the system’s computational power. On the other hand, network performance fluctuations can affect the entire cluster since the network is a shared resource, unlike individual compute nodes that are more easily isolated. Performance fluctuations can adversely affect the utilization of all computational resources. Therefore, maintaining a stable and efficient network is of utmost importance during the training cycle of AI large-scale models, presenting new challenges for network operations.
In the event of a failure during the training task, fault-tolerant replacement or elastic scaling may be required to handle the faulty nodes. When the participating nodes change their positions, the current communication patterns may no longer be optimal, necessitating job redistribution and scheduling to improve overall training efficiency. Additionally, some network failures, such as silent packet loss, can occur unexpectedly. When they happen, they not only reduce the efficiency of collective communication, but also cause communication library timeouts, resulting in long periods of training business being stuck, significantly impacting training efficiency. Therefore, it is necessary to obtain fine-grained information about throughput, packet loss, and other parameters of the business flow. This allows for timely fault detection and self-healing within seconds.
5. Network Automation Deployment Requirements
The construction of intelligent lossless networks often relies on RDMA protocols and congestion control mechanisms, accompanied by a series of complex and diverse configurations. Any misconfiguration of these parameters can potentially impact the performance of the network and may give rise to unexpected issues. Statistics show that over 90% of high-performance network failures are caused by configuration errors. The main reason for such issues is the multitude of configuration parameters for network cards, which depend on architecture versions, business types, and network card types. In the case of large-scale AI model training clusters, the complexity of configuration is further increased. Therefore, efficient or automated deployment and configuration can effectively enhance the reliability and efficiency of large-scale model cluster systems. Automated deployment and configuration require the ability to deploy configurations in parallel on multiple machines, automatically select relevant parameters for congestion control mechanisms, and choose appropriate configurations based on network card types and business types.
Similarly, in complex architectures and configuration conditions, the ability to quickly and accurately locate faults during business operation can effectively ensure overall business efficiency. Automated fault detection enables rapid problem localization, precise notifications to management personnel, and reduces problem localization costs. It facilitates swift identification of the root causes of issues and provides corresponding solutions.
6. Choosing PNA Fiber Accelerate AI Model Network
Based on the analysis above, it is evident that AI large-scale models have specific requirements in terms of scale, bandwidth, stability, latency/jitter, and automation capability. However, there is still a technological gap to fully meet these requirements with the current layout of data center networks.
The demand for network capabilities in AI large-scale models is exceptionally high. These models typically have massive parameter sizes and complex computational requirements, necessitating substantial computing and storage resources to support their training and inference processes. Simultaneously, high-speed network connectivity is essential to ensure efficient data transmission and processing. PNA Fiber offers high-quality connectivity products that meet the needs of AI model network deployment. With its exceptional technical team, PNA Fiber can provide tailored solutions based on the specific circumstances of each customer, enhancing network performance and user experience.
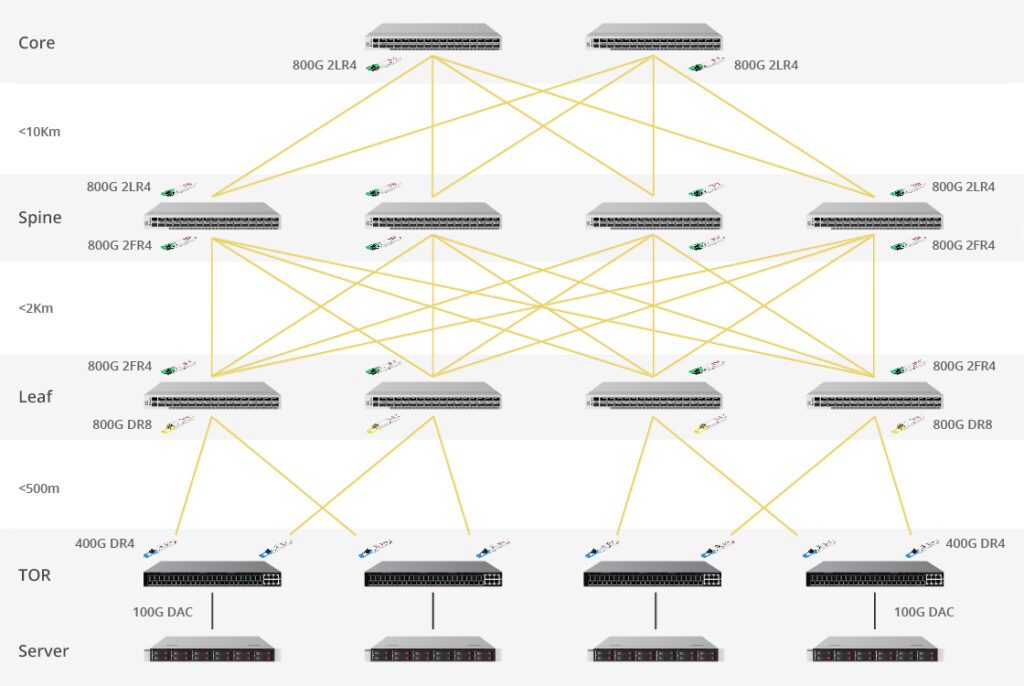
In addition to switches and network cards, PNA Fiber‘s product portfolio includes optical modules with rates ranging from 100G to 800G, as well as AOCs and DACs. These products enable efficient data transmission, accelerating AI model training and inference processes. In large-scale AI training, optical modules connect distributed computing nodes, working collaboratively to accomplish complex computational tasks. With their high bandwidth, low latency, and low error rate characteristics, these products not only expedite model updates and optimization but also reduce communication delays, enabling faster and more efficient artificial intelligence computing.
Choosing PNA Fiber’s connectivity products can enhance the capabilities of data center networks to better support the deployment and operation of AI large-scale models.
For more information, please visit the PNA Fiber official website!